Construire un pipeline OCR intelligent pour les factures fournisseurs
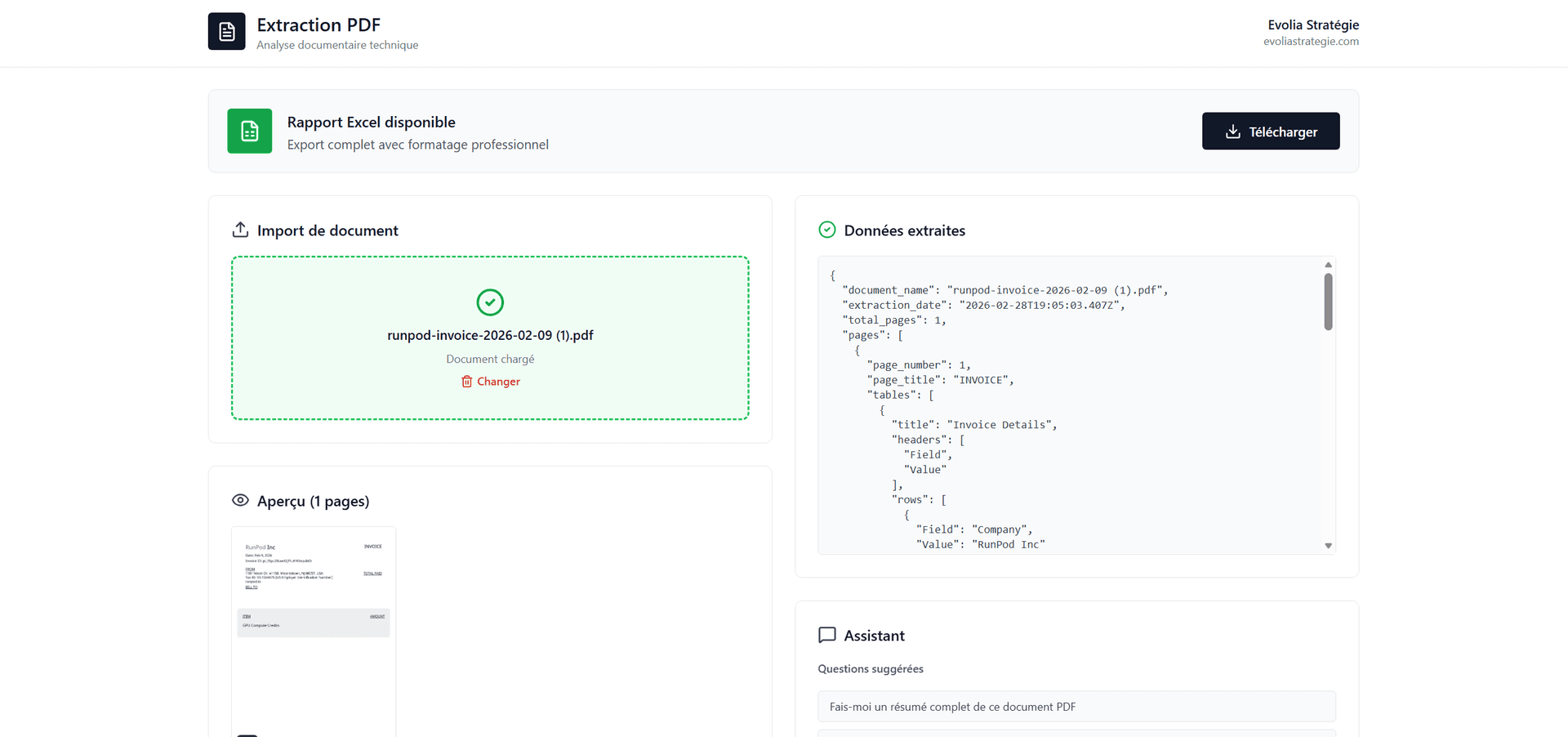
Le traitement des factures fournisseurs est l'un des processus les plus chronophages et les plus sources d'erreurs dans les entreprises. Une PME qui reçoit 500 factures par mois y consacre souvent 40 à 60 heures de travail administratif. Un pipeline OCR intelligent peut réduire ce temps de 85 % tout en améliorant la précision d'extraction.
Architecture d'ensemble du pipeline OCR intelligent
Étape 3 — OCR : choisir le bon moteur
- —Tesseract (open source) : gratuit, suffisant pour les scans de bonne qualité, limité sur les mises en page complexes.
- —AWS Textract / Google Document AI : très performants, mais exposition des données à des serveurs américains — incompatible avec les exigences de souveraineté.
- —Azure Document Intelligence : hébergeable en Europe, bonne performance sur les factures.
- —Surya / Marker (open source) : solutions récentes très performantes, déployables on-premise. Recommandées pour les environnements souverains.
Étape 4 — Extraction intelligente par LLM
Un LLM comme Mistral 7B, alimenté avec un prompt spécialisé, extrait avec fiabilité les champs clés : numéro de facture, date d'échéance, SIRET du fournisseur, lignes de détail, montants HT/TVA/TTC, IBAN. Le LLM retourne ces informations au format JSON structuré. Un score de confiance est associé à chaque champ pour déclencher une validation humaine sur les cas ambigus.
Performances attendues et ROI
85–95 %
Extraction correcte sans intervention
30 sec
Par facture (vs 8 min en manuel)
–90 %
Réduction des erreurs de saisie
3–6 mois
ROI amorti (500 factures/mois)
Architecture souveraine recommandée
Pour les entreprises qui traitent des données financières sensibles, nous recommandons une architecture 100 % on-premise ou sur cloud souverain français : Surya pour l'OCR, Mistral 7B déployé via Ollama ou vLLM pour l'extraction, PostgreSQL pour le stockage des données extraites, et une API REST pour l'intégration avec votre ERP (SAP, Sage, Cegid, Dynamics). Aucune donnée ne quitte votre infrastructure.
Un pipeline OCR intelligent n'est pas un projet de science-fiction. C'est une réalité déployée en production dans de nombreuses PME françaises, avec des délais de mise en œuvre de 6 à 12 semaines et des gains mesurables dès le premier mois.