RAG Multimodal pour Documentation Industrielle
L'application des Large Language Models (LLM) à la documentation industrielle présente un défi singulier : la densité informationnelle n'est pas portée par le texte linéaire, mais par la structure visuelle. Abaques de tolérancement, tableaux de visserie et schémas techniques échappent aux tokenizers classiques. Cet article présente une méthodologie technique pour résoudre ce problème de cécité structurelle en utilisant une stack 100% Open Source.
1. Architecture Globale du Système
L'architecture déployée repose sur une séparation stricte entre le traitement visuel (perception de la page comme une image) et le traitement sémantique (compréhension du sens textuel). Le système s'articule autour d'un orchestrateur central développé en Python, utilisant le framework LlamaIndex pour la gestion des flux de données.
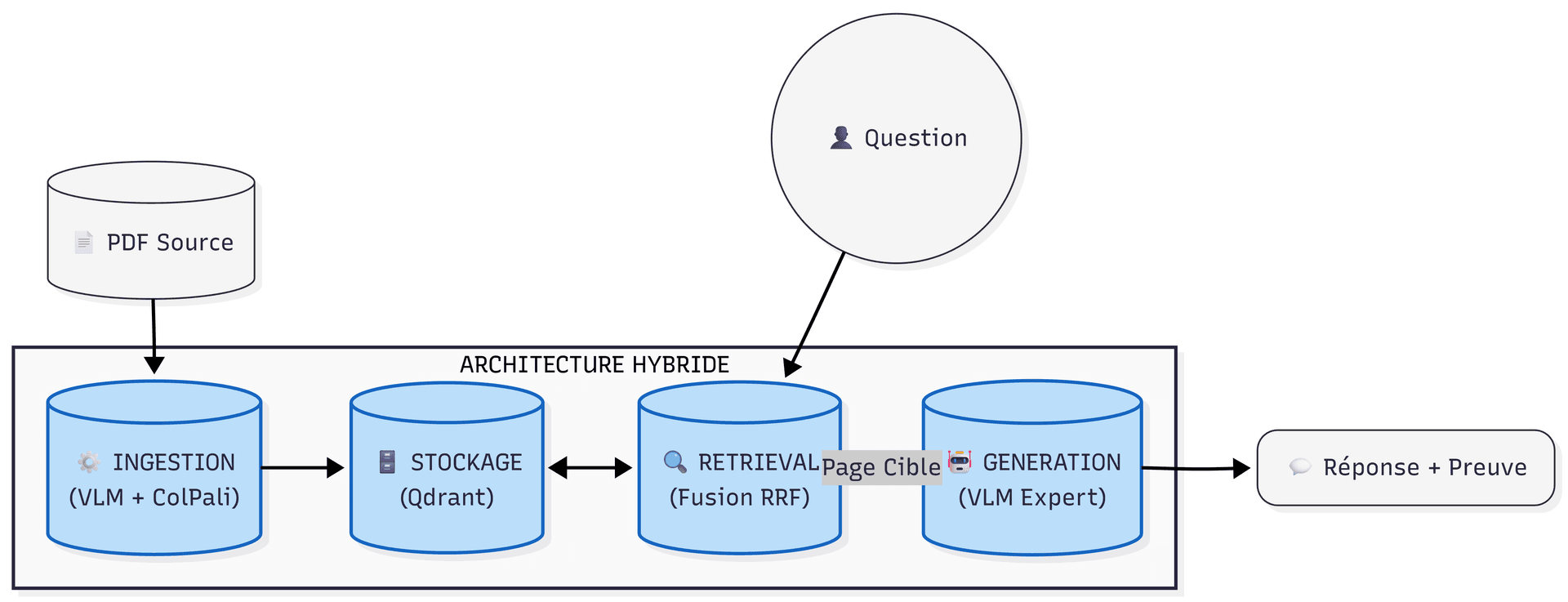
La contrainte de souveraineté et de transparence a guidé le choix de composants exclusivement Open Source :
| Composant | Technologie | Fonction Technique |
|---|---|---|
| VLM / Inférence | Qwen2.5-VL-72B | OCR contextuel, extraction JSON structurée et synthèse de réponse finale. |
| Retrieval Visuel | ColPali (PaliGemma) | Encodage multi-vecteurs des images (Late Interaction) pour la recherche visuelle. |
| Vector Store | Qdrant | Stockage hybride : embeddings denses (ColPali) et payload JSON (Métadonnées). |
2. Pipeline d'Ingestion : La Stratégie de Double Encodage
La phase d'ingestion ne se limite pas à un découpage de texte (chunking). Le document source PDF est d'abord rasterisé (converti en images) à une résolution minimale de 300 DPI pour garantir la lisibilité des caractères de petite taille présents dans les tableaux techniques. Le flux de traitement se divise ensuite en deux branches parallèles.
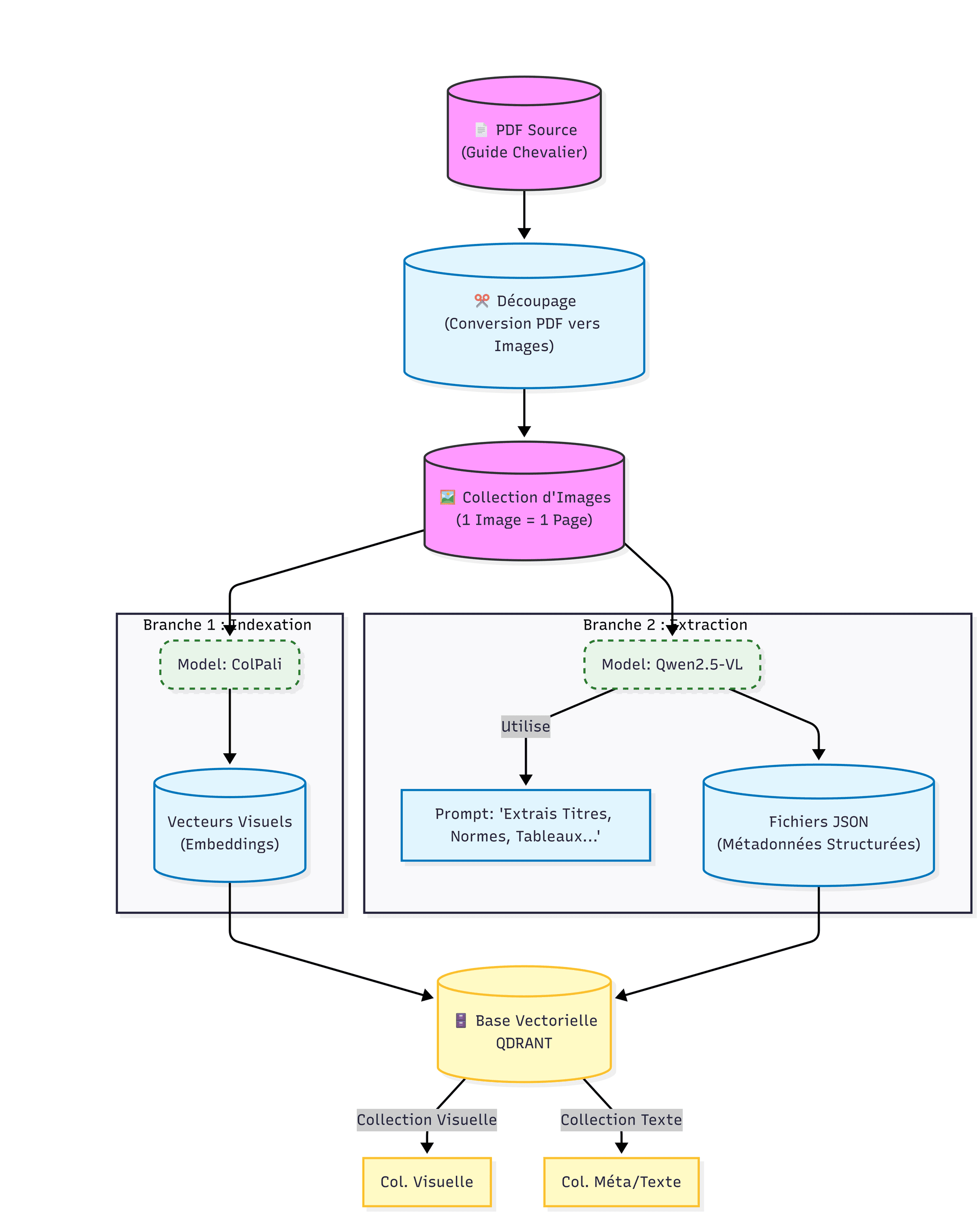
2.1. Branche A : Encodage Visuel Dense (Visual Embeddings)
Nous utilisons ColPali, un modèle basé sur l'architecture ColBERT appliquée à la vision (via PaliGemma). Contrairement aux modèles Bi-Encoder classiques qui compressent un document en un vecteur unique, ColPali génère une matrice de vecteurs (multi-vector representation) pour chaque patch de l'image.
Cette approche permet de conserver la topologie de la page. Le modèle voit la forme d'un tableau ou la disposition d'un schéma. Lors de la recherche, il ne compare pas juste des concepts sémantiques, mais aligne visuellement les zones pertinentes de la requête avec les zones de l'image.
2.2. Branche B : Extraction Sémantique Structurée (Metadata Extraction)
En parallèle, le modèle VLM Qwen2.5-VL est sollicité pour une tâche d'extraction contrainte. Via un prompt système strict, le modèle analyse l'image pour générer un objet JSON contenant :
- Numéros de normes citées (ex: ISO 2768-m)
- Titres et sous-titres de chapitres
- Description synthétique des tableaux présents
Ces métadonnées sont injectées dans le Payload de Qdrant, permettant des filtres exacts (keyword search) impossibles à obtenir avec une recherche vectorielle seule.
3. Pipeline d'Inférence et Retrieval Hybride
La précision du système repose sur sa capacité à réconcilier deux signaux de recherche divergents lors de la requête utilisateur. Nous implémentons un algorithme de fusion de rangs pour déterminer la page la plus pertinente.
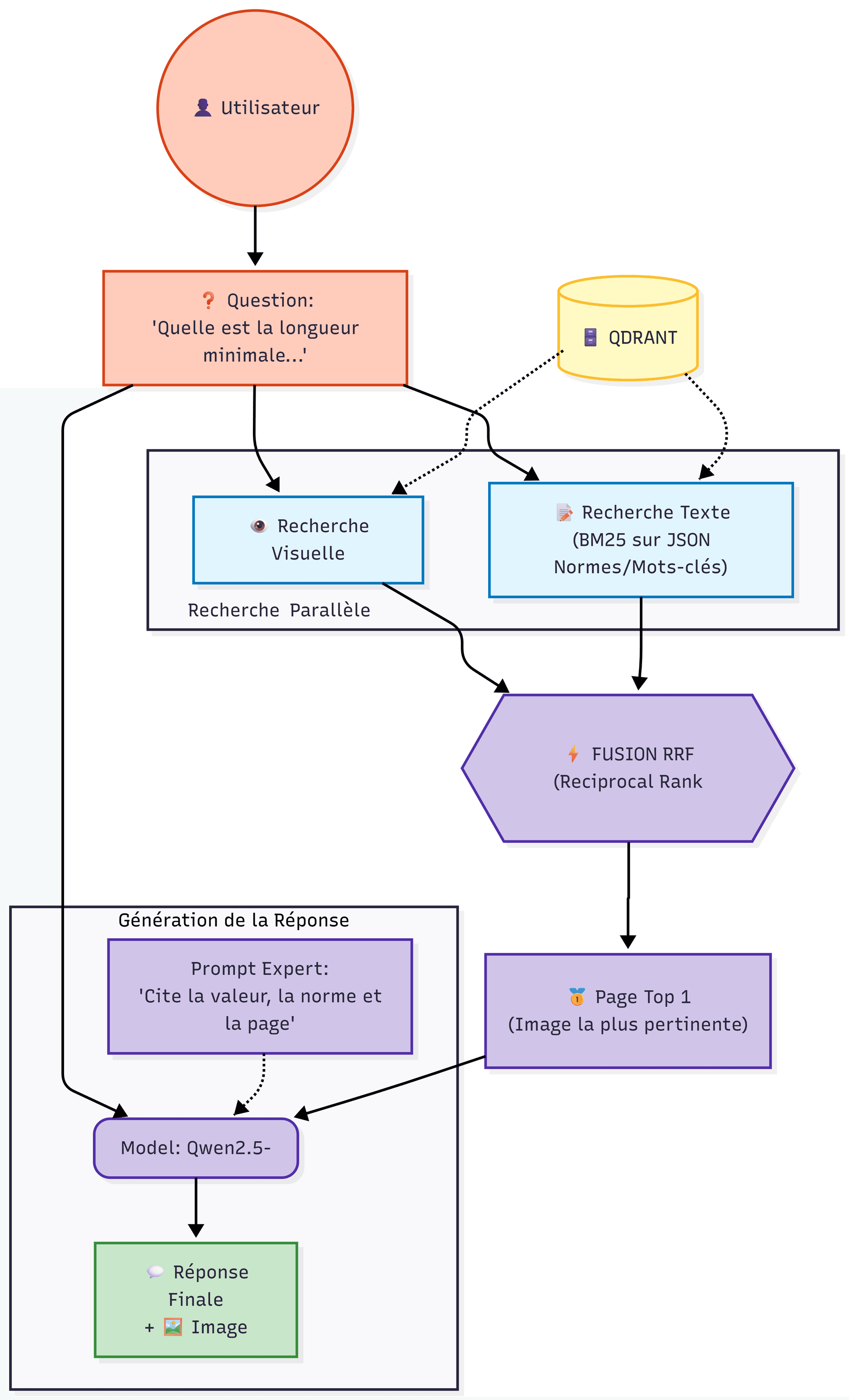
3.1. Mécanisme de Retrieval Parallèle
À la réception d'une requête utilisateur (ex: Quelle est la tolérance pour une vis M4 ?), deux recherches sont lancées simultanément dans Qdrant :
- Recherche Tensorielle (MaxSim) : ColPali calcule le score de similarité maximum entre les patchs visuels de la requête et les pages stockées. Cela permet de retrouver la page contenant le tableau visuel des vis M4, même si le mot 'M4' est noyé dans une grille de chiffres.
- Recherche Lexicale (Keyword/Metadata) : Une recherche classique sur les champs JSON indexés pour capturer les correspondances exactes de termes techniques ou de normes.
3.2. Reciprocal Rank Fusion (RRF)
Les résultats de ces deux méthodes sont normalisés via l'algorithme RRF (Reciprocal Rank Fusion). Le score RRF est calculé pour chaque document $d$ selon la formule :
Où $rank_i(d)$ est la position du document dans la liste de résultats $i$, et $k$ une constante de lissage (généralement 60). Cette méthode permet de favoriser mathématiquement les documents qui apparaissent en bonne position dans les deux listes, éliminant ainsi les faux positifs visuels ou textuels.
4. Génération Multimodale (Grounding)
Une fois la page cible identifiée (Top-1), le système entre dans la phase de génération. Contrairement aux approches RAG texte-seul qui fournissent des fragments de texte au LLM, nous fournissons l'image brute de la page au modèle VLM Qwen2.5-VL.
Cette étape est cruciale pour la fiabilité industrielle. Le modèle 'lit' le tableau directement sur l'image source pour extraire la valeur. La réponse générée inclut systématiquement :
1. La réponse technique précise.
2. La citation de la norme visible sur le document.
3. L'affichage de l'image source pour vérification humaine.
Conclusion
L'architecture hybride présentée démontre que le traitement de la documentation technique ne peut se satisfaire d'une approche purement textuelle. L'intégration de la modalité visuelle via ColPali, combinée à une extraction structurée rigoureuse, permet d'atteindre des niveaux de précision compatibles avec les exigences industrielles, tout en conservant une stack technologique ouverte et auditables.